Apache Spark and PySpark on Databricks: A Comprehensive Guide to IPL Data Analysis

Welcome to the IPL Data Analysis project using Apache Spark and PySpark on Databricks! This project aims to demonstrate the power of big data processing and analytics using Spark, specifically focusing on IPL (Indian Premier League) cricket data. We will leverage the Databricks Community Edition for our computations and showcase how to analyze large datasets efficiently.
What is Apache Spark and PySpark?
Apache Spark is an open-source, distributed computing system that provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. PySpark is the Python API for Spark, which allows you to write Spark applications using Python.
Differences between Apache Spark, PySpark, and Pandas
- Apache Spark: A fast, distributed processing engine suitable for large-scale data processing tasks.
- PySpark: The Python interface to Apache Spark, enabling Python developers to leverage Spark’s power.
- Pandas: A Python library for data manipulation and analysis, ideal for small to medium-sized datasets. Unlike Spark, Pandas operates on a single machine.
Packages Used in This Project
- pyspark: The Python API for Spark, enabling us to use Spark functionalities in Python.
- pandas: A data manipulation library used for smaller data processing tasks.
- matplotlib: A plotting library used for data visualization.
- seaborn: A statistical data visualization library built on top of Matplotlib.
✅Step 1: Create a Databricks Community Edition Account
- Visit the Databricks Community Edition website.
- Click on “Get Started for Free”.
- Fill in your details to create an account.
- Verify your email address and log in to Databricks.
✅Step 2: Create a New Cluster
- After logging in, click on “Clusters” in the left-hand menu.
- Click “Create Cluster”.
- Name your cluster (e.g., “IPL-Analysis-Cluster”).
- Select the appropriate Databricks runtime version.
- Click “Create Cluster”.
✅Step 3: Upload Data to Databricks
You can either upload the data files directly to Databricks or use S3 for storage.
a): Upload Data Directly to Databricks
- Click on “Data” in the left-hand menu.
- Click “Add Data” and select “Upload File”.
- Upload the IPL data CSV files.
OR
b): Use Amazon S3
- If you have your data stored in S3, you can access it directly from Databricks.
- Ensure you have the necessary AWS credentials configured.
- Use the following code snippet to read data from S3:
✅Step 4: Clone the Project Repository
- In your Databricks workspace, click on “Repos” in the left-hand menu.
- Click “Add Repo” and select “Clone Existing Repo”.
- Enter the URL of the repository:
https://github.com/TravelXML/APACHE-SPARK-PYSPARK-DATABRICKS.git - Click “Create Repo”.
✅Step 5: Open the Notebook
- Navigate to the cloned repository in the “Repos” section.
- Open the notebook file
IPL_DATA_ANALYSIS_SPARK_SAP.ipynb.
Running through the code: ultimate code walk-through
Now, let’s dive into the code and understand each step of the analysis. You can follow along with the notebook file from the repository here.
- Step 1: Import Necessary Modules and Functions from PySpark
- Step 2: Create a Spark Session
- Step 3: Define the Schema for the CSV Data
- Step 4: Import S3 Public URL CSV Files into DataFrame
- Step 5: Clean Up and Transform the Data
- Step 6: Data Visualization
✅Step 1: Import Necessary Modules and Functions from PySpark
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
from pyspark.sql.functions import col
import matplotlib.pyplot as plt
import seaborn as snsThese imports are necessary for creating a Spark session, defining schema, handling data, and visualizing data with Matplotlib and Seaborn.
✅Step 2: Create a Spark Session
spark = SparkSession.builder.appName('IPL Data Analysis').getOrCreate()This code initializes a Spark session, which is the entry point to using Spark.
✅Step 3: Define the Schema for the CSV Data
Let’s define the schema to import the CSV data from S3 to Databricks:
# Define the schema for the CSV file
schema = StructType([
StructField("ID", IntegerType(), True),
StructField("City", StringType(), True),
StructField("Date", StringType(), True),
StructField("Season", IntegerType(), True),
StructField("MatchNumber", StringType(), True),
StructField("Team1", StringType(), True),
StructField("Team2", StringType(), True),
StructField("Venue", StringType(), True),
StructField("TossWinner", StringType(), True),
StructField("TossDecision", StringType(), True),
StructField("SuperOver", StringType(), True),
StructField("WinningTeam", StringType(), True),
StructField("WonBy", StringType(), True),
StructField("Margin", IntegerType(), True),
StructField("method", StringType(), True),
StructField("Player_of_Match", StringType(), True),
StructField("Team1Players", StringType(), True),
StructField("Team2Players", StringType(), True),
StructField("Umpire1", StringType(), True),
StructField("Umpire2", StringType(), True),
])ll values
df = df.dropna()This step involves cleaning the data by removing any rows with missing values and selecting relevant columns for analysis.
✅Step 4: Import S3 Public URL CSV Files into DataFrame
Replace 's3a://your-bucket-name/your-file.csv' with the actual S3 public URL of your CSV file.
# Load the CSV file into a DataFrame
df = spark.read.csv('s3a://your-bucket-name/your-file.csv', schema=schema, header=True)
df.show(5)✅Step 5: Clean Up and Transform the Data
Drop Rows with Null Values
df = df.dropna()Select Relevant Columns
df = df.select('ID', 'City', 'Date', 'Season', 'MatchNumber', 'Team1', 'Team2', 'Venue', 'TossWinner', 'TossDecision', 'WinningTeam', 'Margin')
df.show(5)✅Step 6: Data Visualization
Convert Spark DataFrame to Pandas DataFrame for Visualization
pdf = df.toPandas()Plot the Number of Matches per Season
plt.figure(figsize=(12, 6))
sns.countplot(data=pdf, x='Season')
plt.title('Number of Matches per Season')
plt.xlabel('Season')
plt.ylabel('Number of Matches')
plt.show()Plot the Number of Wins per Team
plt.figure(figsize=(12, 6))
sns.countplot(data=pdf, y='WinningTeam', order=pdf['WinningTeam'].value_counts().index)
plt.title('Number of Wins per Team')
plt.xlabel('Number of Wins')
plt.ylabel('Team')
plt.show()Plot Margin of Victory
plt.figure(figsize=(12, 6))
sns.histplot(data=pdf, x='Margin', bins=30, kde=True)
plt.title('Distribution of Victory Margin')
plt.xlabel('Margin of Victory')
plt.ylabel('Frequency')
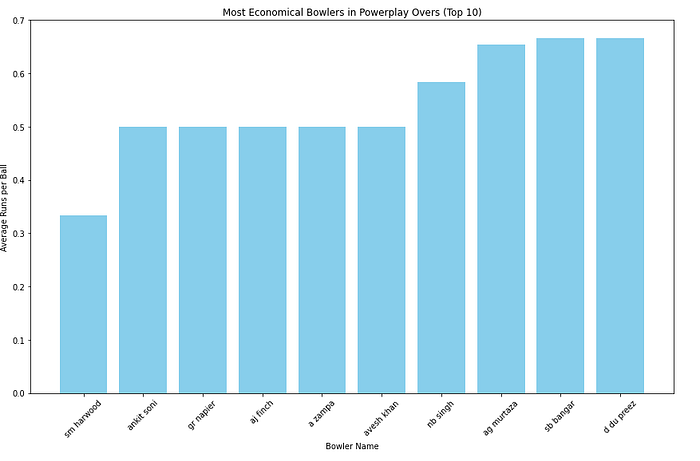
plt.show()Economical Bowlers in Powerplay
# Assuming 'economical_bowlers_powerplay' is already executed and available as a Spark DataFrame
economical_bowlers_pd = economical_bowlers_powerplay.toPandas()
# Visualizing using Matplotlib
plt.figure(figsize=(12, 8))
# Limiting to top 10 for clarity in the plot
top_economical_bowlers = economical_bowlers_pd.nsmallest(10, 'avg_runs_per_ball')
plt.bar(top_economical_bowlers['player_name'], top_economical_bowlers['avg_runs_per_ball'], color='skyblue')
plt.xlabel('Bowler Name')
plt.ylabel('Average Runs per Ball')
plt.title('Most Economical Bowlers in Powerplay Overs (Top 10)')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()Output:
The outcome of the match depends on winning the toss
#The purpose of this code is to analyze and visualize the impact of winning the toss on match outcomes in cricket.
# It converts the Spark DataFrame toss_impact_individual_matches to a Pandas DataFrame and then uses Seaborn and Matplotlib
# to create a count plot that shows the number of matches won and lost by teams that won the toss.
toss_impact_pd = toss_impact_individual_matches.toPandas()
# Creating a countplot to show win/loss after winning toss
plt.figure(figsize=(10, 6))
sns.countplot(x='toss_winner', hue='match_outcome', data=toss_impact_pd)
plt.title('Impact of Winning Toss on Match Outcomes')
plt.xlabel('Toss Winner')
plt.ylabel('Number of Matches')
plt.legend(title='Match Outcome')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()Output:

In the future, we will explore an article using the new IPL dataset with Apache Spark and its built-in MLlib machine learning techniques to predict the most in-demand cricketers for each team. Let’s delve into the minds of IPL franchises.
. Thoughts
Congratulations! You’ve now learned the basics of Apache Spark and PySpark, and how to perform data analysis and transformation on a large dataset using Databricks. You’ve seen how to import data, clean and preprocess it, and visualize it to uncover meaningful insights. With these skills, you’re well on your way to becoming proficient in big data analytics.
For more articles related to Apache Spark for Machine Learning on Databricks, visit my GitHub repository:
Apache Spark PySpark Databricks Machine Learning MLlib
If you found this Article is helpful and want to learn more about advanced techniques in Apache Spark, PySpark, and data science in general, make sure to subscribe for more in-depth tutorials and articles. Happy analyzing!
For future article, You can subscribe.
👏👏👏 If you enjoyed reading this post, please give it a clap 👏 and follow me on Medium! 👏👏👏
Cheers!
